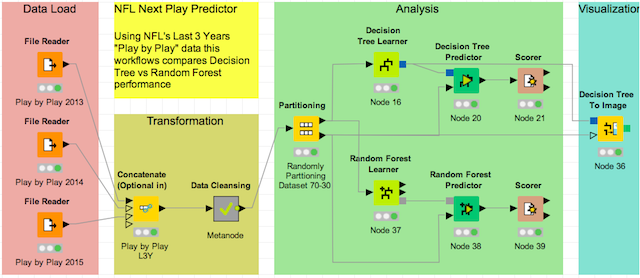
NFL next play prediction
My take on AI in American Football
After Money Ball, sport teams across the world want to gain advantages based on data. Even foosball tables store data now.
Earlier this week I ran across an article from Wired named Football Coaches Are Turning to AI for Help Calling Plays. Apparently this isn’t a new thing, so I decided to give it a try using KNIME. I must emphasize in “give it a try” since we only have 2 weeks left of NFL and then the fuss will be gone until next September.
If you are not familiar with KNIME I hope this works as an introduction to this multi-language platform. Otherwise, if you know your way around these type of nodes, then I look forward to discussing better ways to do this.
We’ll follow the next steps in KNIME to create a model that predicts the next play:
- Data Load: Load “Play by Play” data
- Transform: Filter, Split, Clean, Edit, Etc…
- Analysis: Create Model and use it to Predict next play
- Visualization: View what’s the model like
1. Data Load
WE NEED DATA! (not Foosball data though). Goggling “NFL play by play stats” could lead you to almost buying a ~1,200 USD subscription to daily NFL stats updates. Since I don’t have that amount to spend on this I will use the last 3 seasons available at NFL savant.
My KNIME workflow starts with the data load section. This section contains a node per file to read - and load - into the workflow.
You can use two different nodes to read csv files: File Reader or CSV Reader. The first one is more general and flexible than the latter. That’s why I recommend you to get familiar with it.
2. Transform
Once the data is “ready to rumble”, we need to create a single table containing all 3 files. The “Concatenate Node” does the same thing as the rbind() function in R. It puts one table after another, with the only requirement that it has to have the same columns.
![]()
The grey node is a metanode. It’s a bunch of nodes within a node. The metanode takes the concatenated table, then it removes NAs out, split columns that we aren’t going to use in our model, and lastly filter only PASSING and RUSHING plays.
The NFL changed the rule for extra points and/or 2-point conversions taking all the surprise effect out it. In addition, there are so many fake punts and field goals that it will only add noise to our model. Also, the other “Play by Play” prediction models only predict passes or rushes.
3. Analysis
Now that we have the data that we need, in the format that we need, we are going to use the “partitioning” node to randomly split the data 70-30 (training-testing). Then we take 2 classification approaches:
- decision tree
- random forest
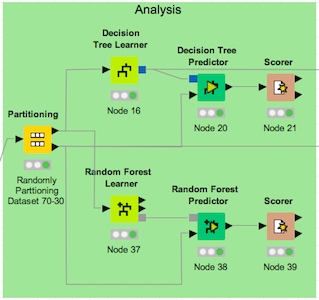
The decision tree model gives us ~68% accuracy while the random forest model goes up to ~73% accuracy. We’ll come back to these values later.
4. Visualization
Using the “Decision tree to Image” node can give us an idea of how complex our decision tree is:
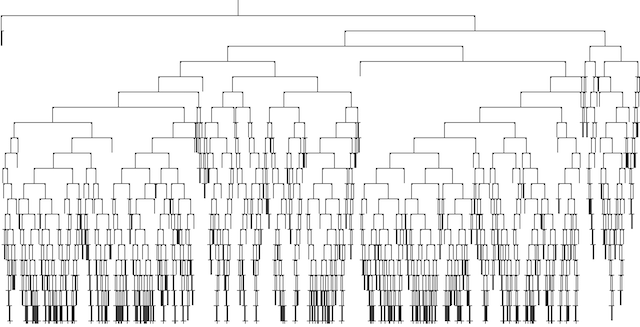
How good is our model?
Well, according to Science Daily having ~68% or ~73% is not bad at all! In this article they mention that they got an average of 75%accuracy across 20 games. They use a logistic regression model for each quarter of the game to increase accuracy. Our Random Forest model performs as good as theirs during the same validated games:
2014 Dallas Cowboys at Jacksonville Jaguars:
- Accuracy for the other model: 91.6%
- Our KNIME model Accuracy:
95.7%
2013 Baltimore Ravens at Denver Broncos:
- Accuracy for the other model: 90.5%
- Our KNIME model Accuracy:
90.72%
Not to shabby for a simple KNIME model! If you like you can download a *.zip version of this workflow here. From here, you could add weather, player info, or any other type of data that you think it could help your model. I guess that the colder it gets, the more rushing plays there will be. Or the better the QB the more passes you will have.
Looking forward to hear your feedback.
Subscribe
Subscribe to this blog via RSS.
Categories
R 2
Plotly 1
Knime 1
Leaflet 1
Inegir 1
Retail 2
Español 2
Recent Posts
-
 Posted on 29 Jun 2016
Posted on 29 Jun 2016
-
Posted on 29 Jun 2016
-
 Posted on 31 Jan 2016
Posted on 31 Jan 2016
-
 Posted on 25 Jan 2016
Posted on 25 Jan 2016
Popular Tags
Rtodolist (3) R (2) Web scraping (1) Plotly (1) Knime (1) Machine learning (1) Random forest (1) Leaflet (1) Inegir (1) Retail (2) Español (2)